
こちらはVcot全体の設定について説明するページです。Vcot全体の設定なので、アバター変更をしても設定は変わりません。
Vcotを右クリック→設定→全体設定から設定できます。
設定した後に右下の保存ボタンを押すと全て保存されます。
基本
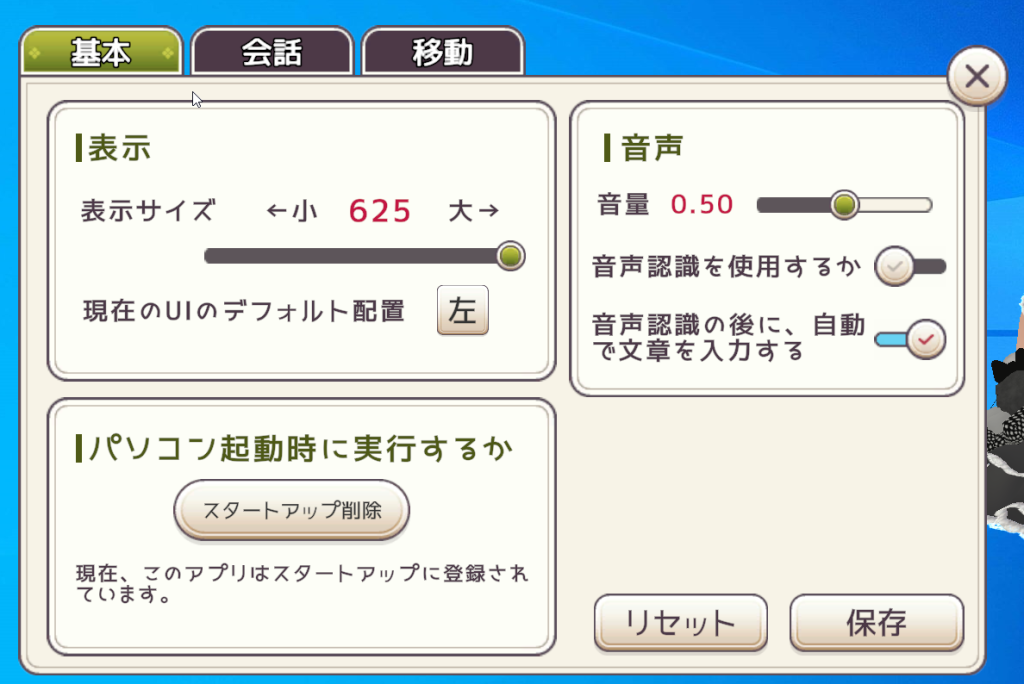
■表示
カメラサイズを変えるとUI、キャラを含めた全てが拡大・縮小されます。カメラサイズは保存を押さないと反映されません。キャラだけサイズ変更したい方はこちら
UIのデフォルト配置を右に変えるとフキダシや設定画面などがキャラの右側に表示されるようになります。
例えばキャラクターがディスプレイの右側にいる時にデフォルト配置を右にしても、フキダシは左に表示されます。これはフキダシなどのUIがディスプレイの外側に表示されて見えないことを防ぐための仕様です。(キャラを左右にドラッグしてみるとよく分かると思います。)
■パソコン起動時に実行するか
パソコンを起動した際にVcotを起動するかどうかの設定です。Vcotのアドレスに全角文字が含まれている場合はスタートアップ登録に失敗しますので、その場合はユーザー側で登録お願いします。
■音声
音量:Vcotの音量のことです。
音声認識を使用するか:音声認識を使用するかどうか。OFFにするとマイクボタンがなくなります。音声認識機能は現在挙動不安定であり、修正予定です。
音声認識後の自動入力:音声認識の自動入力機能を使用するかどうか。ONにするとユーザーが喋った後に自動で喋った内容が送信されます。OFFにすると喋った内容をユーザーが自分で送信ボタンを押して送信するシステムになります。
会話
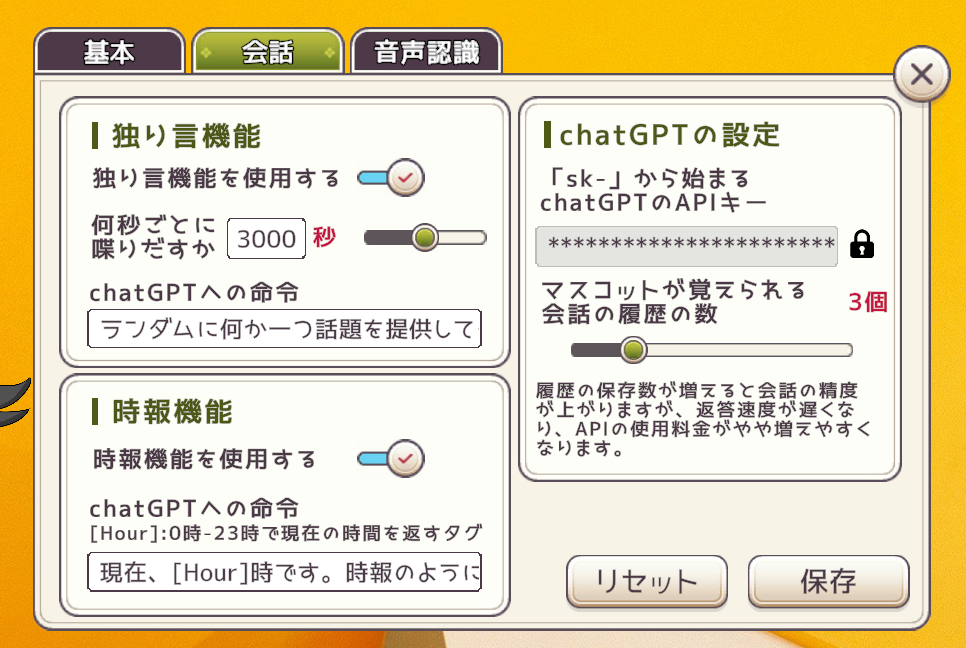
■独り言機能
独り言機能とは設定した時間ごとにキャラクターが勝手に喋りだす機能のことです。ユーザーから話しかけなくても勝手に話しかけてきます。秒数を小さく設定するとVcotがたくさん話してくれますが、その分APIの使用料が高くなるので注意です。
何秒ごとに喋りだすかに関しては、実際には設定した数値の0.8倍~1.2倍がランダムで設定されます。これはキャラクターの生きている感の演出です。
chatGPTへの命令は独り言の際に送信される命令です。
■時報機能
時報機能とは◯時00分ぴったりの時間にキャラクターが時間を教えてくれる機能です。windows内の時間を参照しています。
chatGPTへの命令は独り言の際に送信される命令です。[Hour]は今の時間が入るタグであり、必須のものではないですが、このタグを使わないとVcotは今何時かを知ることはできません。
■chatGPT
chatGPTに送信するchatGPTのAPIキーの設定です。APIキーに関してはロックを外してから編集が可能です。配信、スクリーンショットなどでAPIキーが漏洩しないように普段は隠してあります。
履歴の保存数というのはchatGPTへ送信する履歴の数となります。例えば、
会話内容
ユーザー:こんにちは
マスコット:はろー!
ユーザー:しりとりしよう
マスコット:いいですよ! 理科!
ユーザー:かみ
マスコット:みかん!
ユーザー:「ん」って言ったね
こういった会話をしていたとき、履歴保存数が5個の場合は
マスコットの記憶領域
ユーザー:しりとりしよう
マスコット:いいですよ! 理科!
ユーザー:かみ
マスコット:みかん!
ユーザー:「ん」って言ったね
ここまで覚えているので、マスコットは「間違えました!」などと言った返答をしてくるかもしれません。
ただ、履歴保存数が1個の場合は
マスコットの記憶領域
ユーザー:「ん」って言ったね
マスコットはユーザーの直近の発言しか記憶していないため、マスコットはしりとりしていたことも忘れ「んってなんですか!?」などと言った返答をしてくるかもしれません。
つまり、履歴保存数が多ければ多いほど精度の高い会話ができるということです。
ただし、履歴保存数が多ければ多いほどchatGPTからの返答が遅くなり、料金もやや高くなるので、精度を取るか利便性を取るかで設定は変わってきます。
音声認識
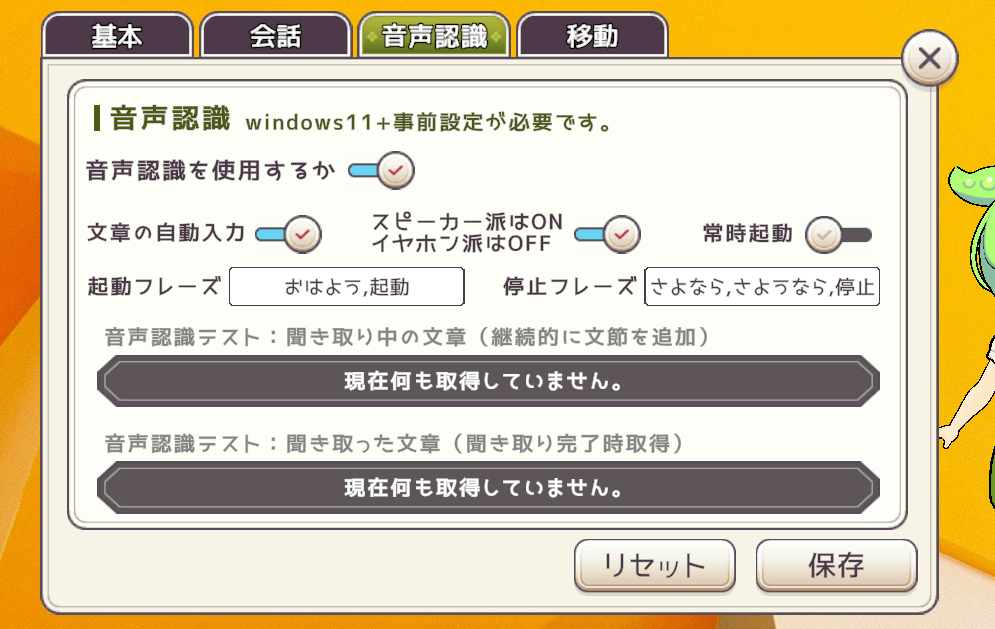
こちらは音声認識機能の設定です。ユーザーがマイク越しに話しかけたときに、Vcotがそれを認識して、発話するか否かの設定となっています。
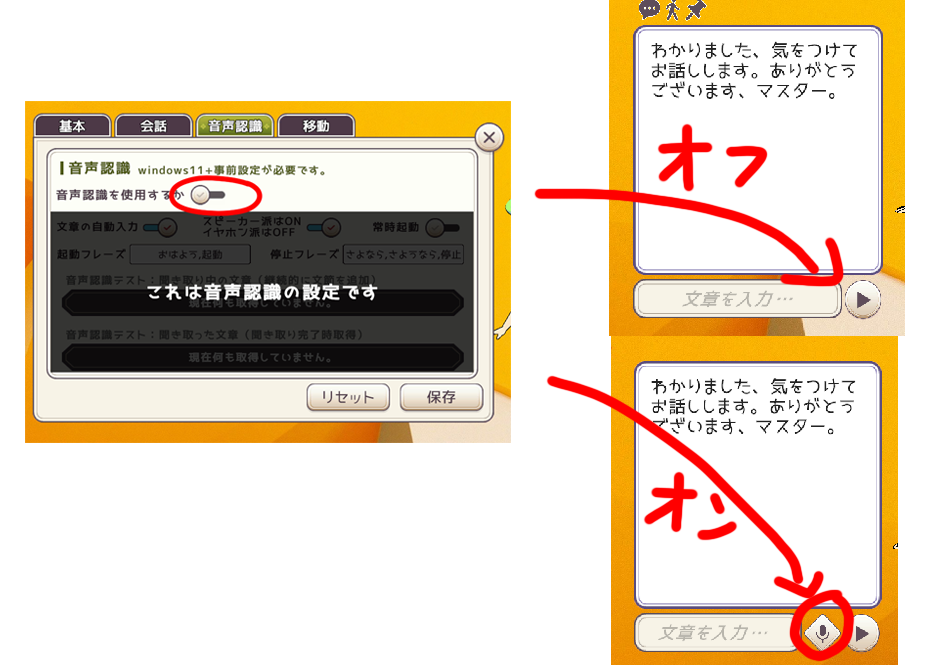
音声認識機能をONにすると、マイクボタンが現れます。このマイクボタンをONの状態でVcotに話しかけると、自動で文字起こしされ、Vcotと実際に会話できるような体験ができます。
音声認識をONにするか マイクボタンを表示・非表示にします。
文章の自動入力 文字を自動で送信するかどうかです。ONにした場合は自動で送信されます。自分で▶ボタンを押したい場合はOFFにしてください。
スピーカー派はON、イヤホン派はOFF Vcotの発話そのものをマイクが拾ってしまい、VcotがVcotに話しかけ続ける無限ループになってしまうのを防ぐための設定です。
常時起動 音声認識後にマイクボタンを無効化する設定です。
VcotをSiri、Alexaのような音声アシスタントとして使う場合は、ここをOFFにして、使いたいときだけ起動フレーズでVcotを起こすような運用がおすすめです。
Vcotと常に会話したい方や、配信に使う方などは、いちいちマイクボタンを押すのが手間になりますので、ONがおすすめです。
起動フレーズ Vcotのマイクボタンを登録した言葉で有効化する機能です。「Hey Siri」「OK Google」「Alexa」にあたるものです。
「,」を挟むことで複数設定できます。
「こんにちは」を「今日は」と聞き取るなど、Vcotが微妙に聞き間違えることがあるので、下の音声認識テストを参考に設定してください。
停止フレーズ Vcotのマイクボタンを登録した言葉で無効化する機能です。
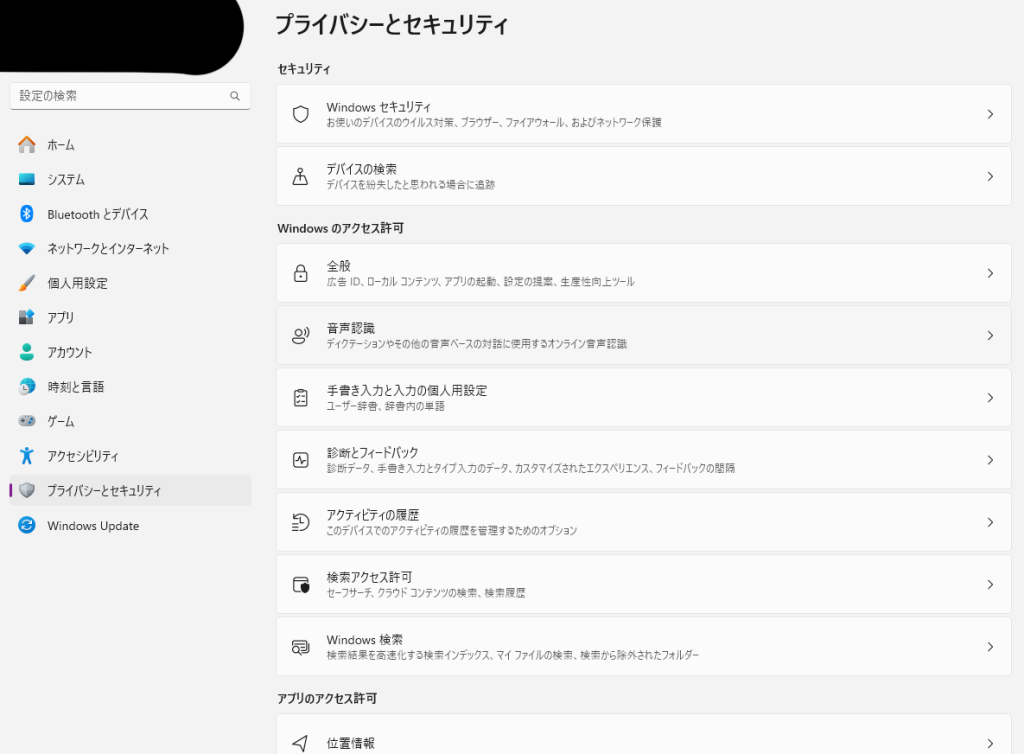
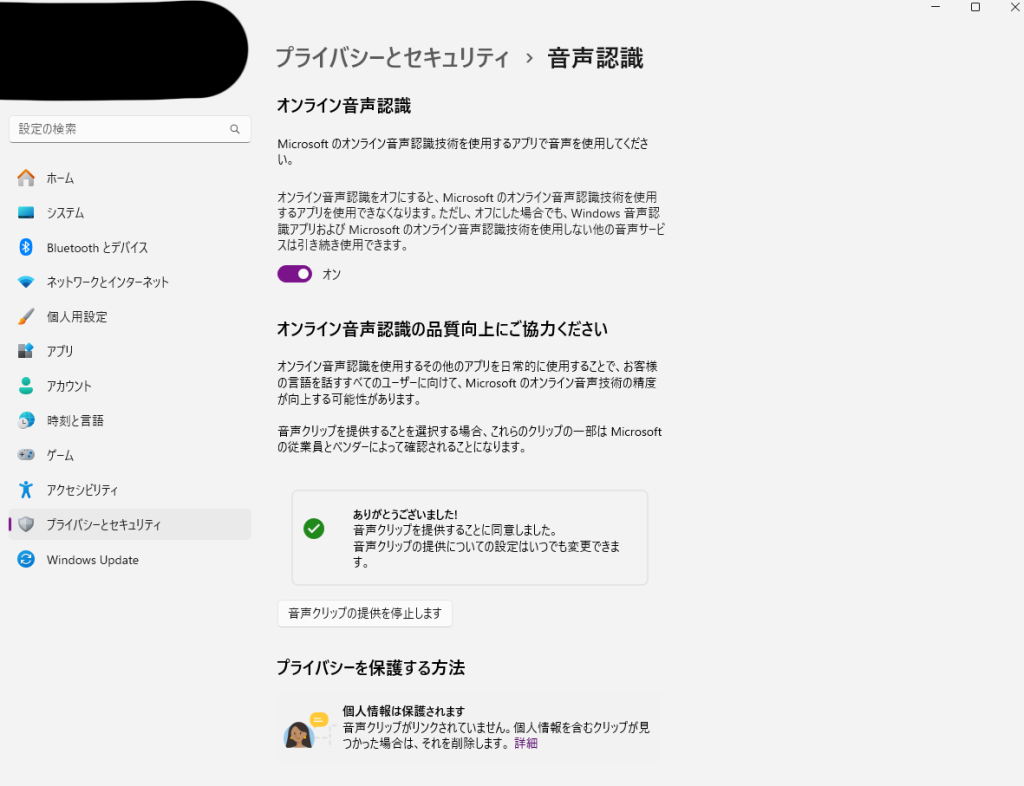
※この機能はwindows11の音声認識機能を使っており、事前に設定が必要です。スタートを右クリックして、設定を開いてください。「設定→プライバシーとセキュリティー→音声認識→オンライン音声認識をオン」で音声認識を有効化する必要があります。またこの機能にはインターネット接続が必須です。
移動
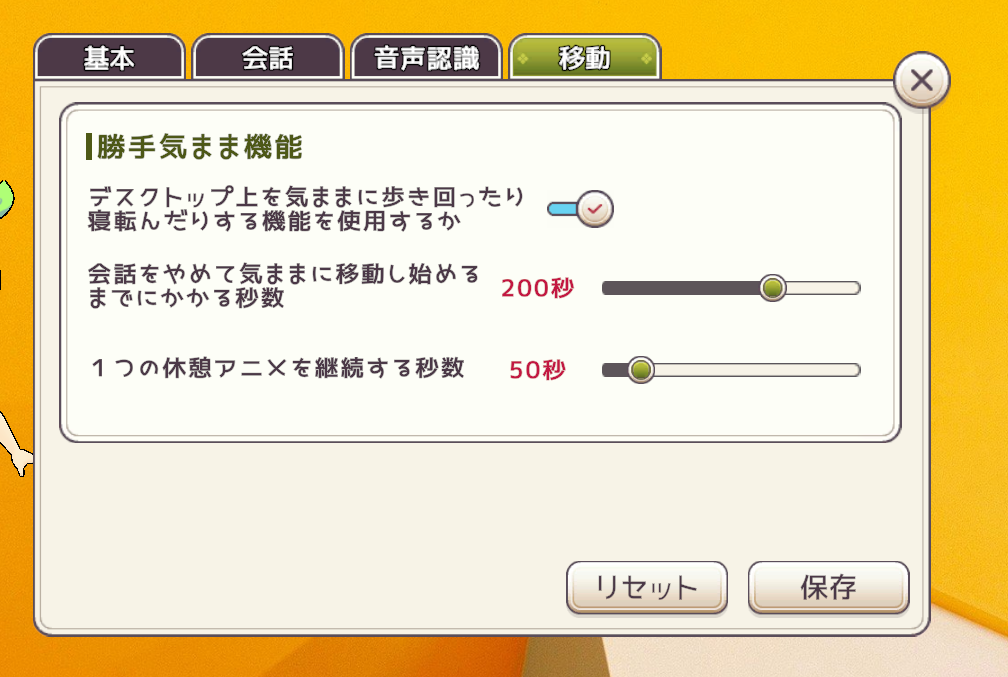
キャラクターはデスクトップ上を気ままに歩き回ったり座ったり寝転んだりします。
キャラクターは最初「会話フェーズ」です。しばらく放置していると、ランダムで「休憩フェーズ」や「移動フェーズ」になり、そこから「会話フェーズ」に戻り、またランダムで「休憩フェーズ」や「移動フェーズ」になり、そこから「会話フェーズ」に戻り…というのを繰り返します。
Vcotをクリックすると気ままに動く機能は停止します。
この機能をOFFにするとキャラクターは一生会話フェーズのままその場に留まり続けます。
遷移秒数に関しては設定した数値の0.5倍から1.5倍の数字がランダムで設定されます。これはキャラクターの生きている感の演出です。

仕様の説明
この項目は高度な内容になっているので、読み飛ばして大丈夫です。
全体設定はテキストとして保存されています。Vcotフォルダにglobal_setting.txtというテキストファイルが入っており、これが全体設定となっています。
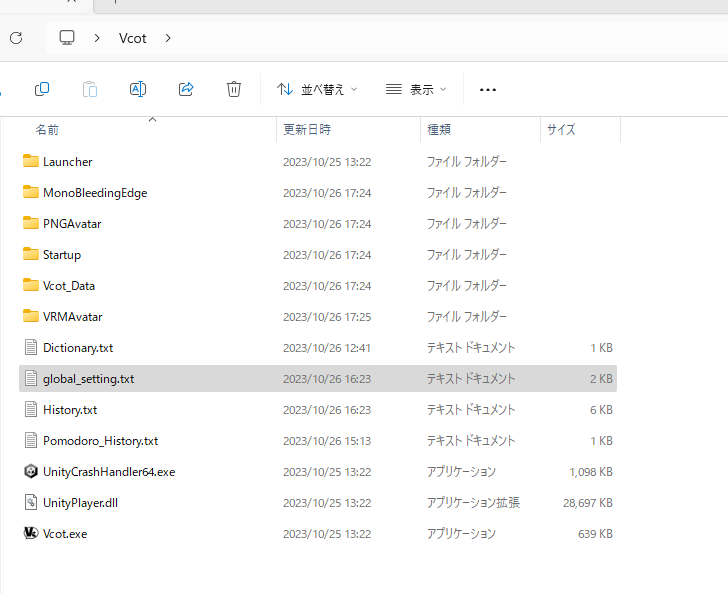
このテキストファイルにはあなたが発行したAPIが記載されているため、他人へ見せたり共有することは推奨されません。APIが知られた場合、chatGPTが他人の金で使い放題になるということです。(実際にはchatGPTには使用上限があり、APIを停止することも可能なので悪用されても2000円ぐらいでしょうが… APIを停止したい場合はこちらからAPIを削除してください)
全体設定のテキストファイルを削除すると、次回起動時に初期化された状態で自動的に作成されます。APIもなくなって再発行が必要になるので注意です。
global_setting.txtの書き換え
この項目は高度な内容になっているので、読み飛ばして大丈夫です。
全体設定のテキストファイルを直接書き換えることは推奨されていませんが、実際的には可能です。「設定項目(default:デフォルトの値):設定内容」という形式で保存されており、「設定内容」部分だけ変更することで改変が可能です。改行するとおかしくなってしまう可能性があるので絶対に改行をしないでください。
ユーザーがあまりいじらなそうな部分は設定UIで実装しておらず、テキストの書き換えでのみ変更可能です。現在のバージョンでは「ぶいこっと複数起動時の会話回数」「タイマー使用時にAPIを使うか」などがこれに当たります。
タイマー使用時にAPIを使うか(default:true):true
↓
タイマー使用時にAPIを使うか(default:true):false例えばこのように変更すると、タイマー終了時に発言するセリフが簡素でAIを使っていないものに変更されます。
以下はテキストにおける設定一覧です。
設定UIからいじれず、テキスト書き換えでのみ変更できる項目は赤文字になっています。逆に言うと赤文字以外の部分をテキスト書き換えで変更する必要はないということです。
テキスト設定の変更反映にはVcotの再起動が必要です。
基本タブに該当するもの
カメラサイズ(default:2):2
表示サイズのことです。設定UIとは全く違う数字になっています。これは内部的にUnityのOrthographicSizeに対応しています。この数字の逆数を取って1000倍した数字が設定UIに表示されています。
UIを左に表示するか(default:true):true
trueだと左、falseだと右になります。
音量サイズ(0が最小,1が最大)(default:0.5):0.5
0が最小,1が最大の音量です。
音声認識機能を使用するか(default:false):false
音声認識後の自動入力をONにするか(default:true):true
音声認識を常時起動しておくか(default:false):false
Vcotが声を発している時に音声認識を一時停止するかどうか(default:true):true
音声認識関連です。trueだと有効化、falseだと無効化されます。
音声認識の起動フレーズ(,で分割)(default:おはよう,起動):おはよう,起動
音声認識の停止フレーズ(,で分割)(default:さよなら,さようなら,停止):さよなら,さようなら,停止
音声認識のフレーズ登録です。
会話タブに該当するもの
たまに喋りだす機能をONにするか(default:false):false
独り言機能です。trueだと有効化、falseだと無効化されます。
たまに喋りだす際のchatGPTへの命令(default:ランダムに何か一つ話題を提供してください。):ランダムに何か一つ話題を提供してください。
独り言機能の命令です。
何秒ごとに喋りだすか(乱数のうち最小値)(default:2400):2400
何秒ごとに喋りだすか(乱数のうち最大値)(default:3600):3600
独り言機能をどれくらいの頻度で行うかの設定です。設定UIで設定したものの0.8倍~1.2倍が設定されます。
ChatGPT_API(default:):
chatGPTのAPIキーがここに保存されています。ここは絶対に人に見られないようにしましょう。
chatGPTの履歴の保存数(default:3):3
chatGPTに送信する会話の保存数です。
移動タブに該当するもの
気ままに移動するかどうか(default:true):true
気ままに移動するかどうかの設定です。trueだと有効化、falseだと無効化されます。
移動状態・休憩状態から別の移動状態・休憩状態への遷移にかかる秒数(乱数のうち最小値)(default:25):25
移動状態・休憩状態から別の移動状態・休憩状態への遷移にかかる秒数(乱数のうち最大値)(default:75):75
会話状態から移動状態・休憩状態への遷移にかかる秒数(乱数のうち最小値)(default:100):100
会話状態から移動状態・休憩状態への遷移にかかる秒数(乱数のうち最大値)(default:300):300
設定UIで設定した数値の0.5倍と1.5倍が設定されます。
タイマー機能(設定はタイマー機能から)
[ポモドーロ]次のフェイズを自動開始するか(default:true):true
trueだと有効化、falseだと無効化されます。
[ポモドーロ]作業時間は何分か(default:25):25
[ポモドーロ]短い休憩時間は何分か(default:5):5
[ポモドーロ]長い休憩時間は何分か(default:10):10
[ポモドーロ]ポモドーロ何回ごとに長い休憩時間を挟むか(default:4):4
[ポモドーロ]何時にリセットするか(default:0):0
全てポモドーロ設定と同じ内容です。
タイマー使用時にAPIを使うか(default:true):true
trueだと有効化、falseだと無効化されます。
タイマー使用時にAIを使って違うセリフを喋るかどうかの設定です。falseにするとタイマー終了時に発言するセリフが簡素でAIを使っていないものに変更されます。
主にchatGPTの使用料を節約するための設定です。
その他
ぶいこっと複数起動時の会話回数(default:2):2
Vcot複数起動時の特殊な設定です。細かくはこちら
表情変化の後、何秒で通常に戻るか(default:40):40
表情が変わった後、一定時間の後に通常に戻る機能があります。
この時間を40秒から変更可能です。
10より小さい数字を指定した場合は自動的に10秒に設定されます。これは数値が小さすぎるとバグのような挙動に見えるための処理です。
chatGPTのモデル(default:gpt-3.5-turbo):gpt-3.5-turbo
chatGPTのモデルを変更にできます。例えば、gpt-4などが設定可能です。現状ではgpt-3.5-turboが最も値段と性能のバランスが良く、高性能のモデルを使うと一気に使用料金が10倍(!?)とかに増えるので注意して設定してください。
OpenAIが現在公開しているモデル一覧はこちら
OpenAIが現在公開しているモデルの使用料金一覧はこちら
chatGPTは現状成長が著しいサービスなので、変化も著しく、このマニュアルでは細かいモデルの説明などは記載しません。画像取り込みのDALL·Eや音声認識のWhisperなどここでは選択できないモデルもたくさんあるので要・試行錯誤です